
By using AI accelerated human annotation this framework removes uncertainty and introduces reliability via a Chain-Of-Thought baseline.
Introduction
There are emergent abilities being discovered concerning Large Language Models (LLMs), these abilities are in essence different ways in-context learning (ICL) is leveraged within LLMs.
LLMs excel at ICL and it has been shown in the recent past that with effective task-specific prompt engineering LLMs can produce high-quality answers.
Question and answer tasks with example-based prompting and CoT reasoning is particularly effective.
The concern of a recent study is that these prompt examples might be too rigid and fixed for different tasks.
This approach follows a methodology which is gaining popularity in recent studies and developments. This procedure includes the following elements:
- Human annotated and vetted data.
- Leveraging one or more LLMs for intermediate tasks prior to the final inference.
- Adding flexibility to the prompt engineering process demand the introduction of complexity and some sort of framework which manages the process.
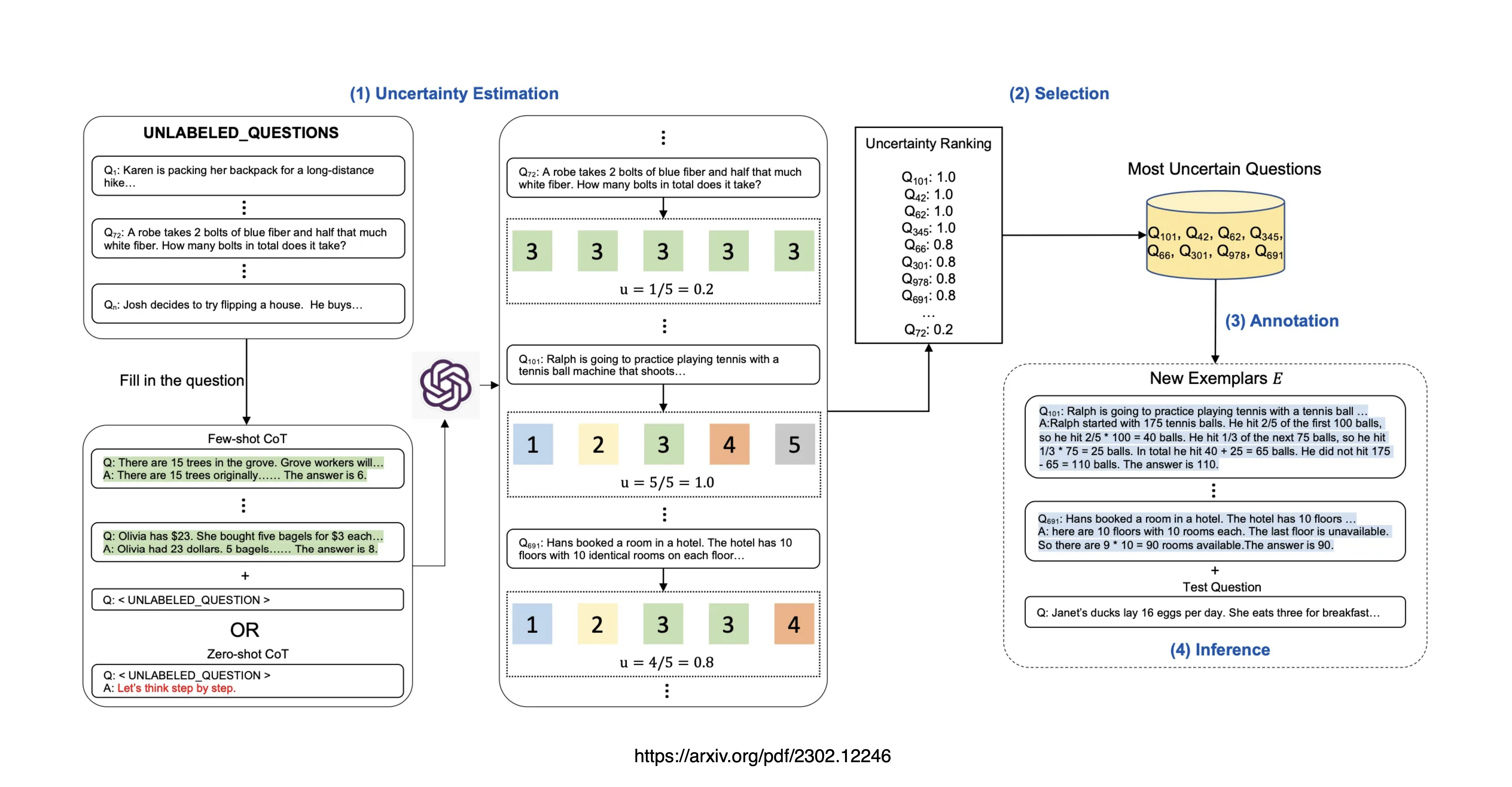
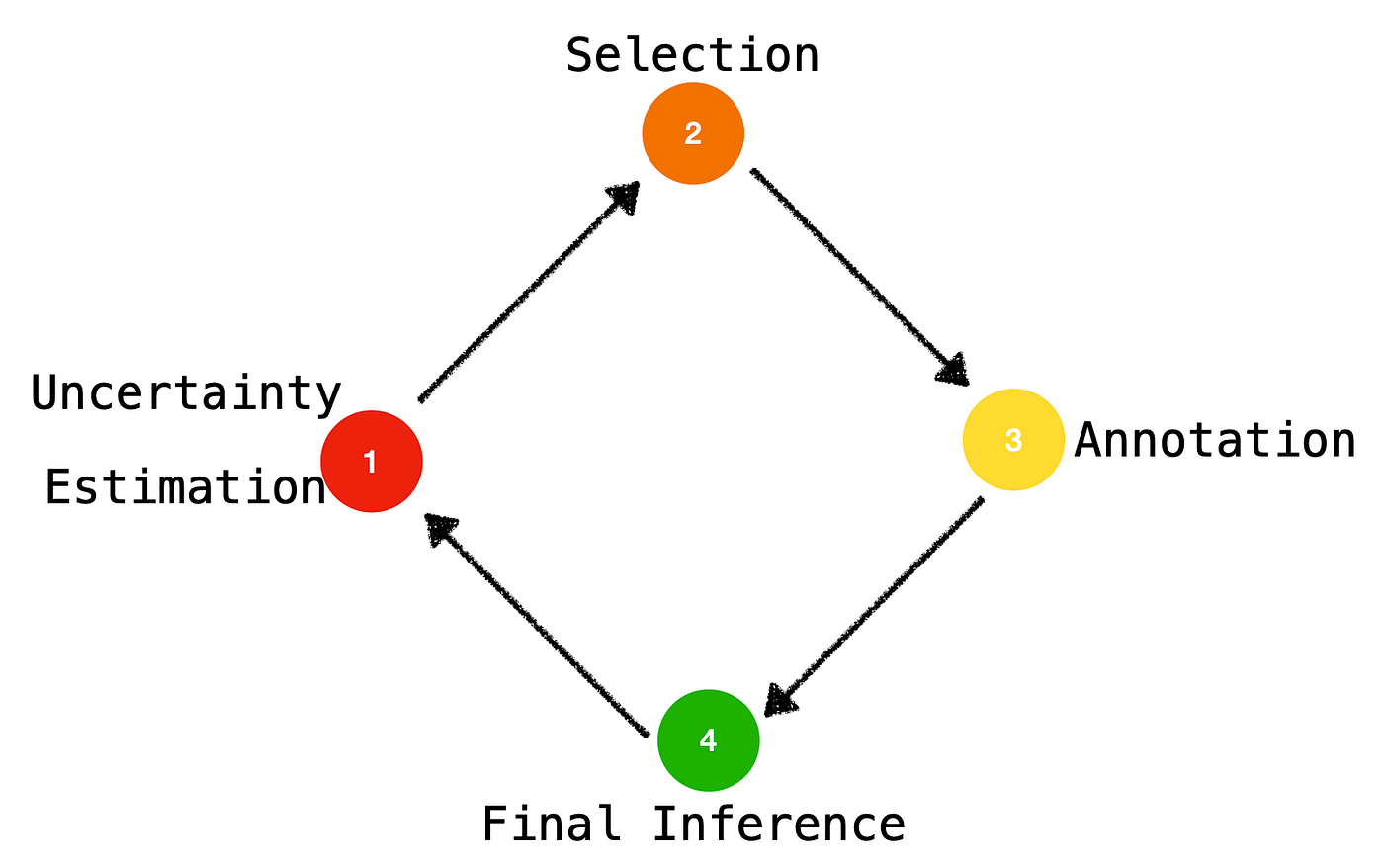
The Four Steps Of Active Prompting
- Uncertainty Estimation
- Selection
- Annotation
- Final Inference
Uncertainty Estimation
The LLM is queried a predefined number of times, to generate possible answers for a set of training questions. These answer and question sets are generated in a decomposed fashion with intermediate steps.
An uncertainty calculator is used based on the answers via an uncertainty metric.
Selection
Ranked according to the uncertainty, the most uncertain questions are selected for human inspection and annotation.
Annotation
Human annotators are used to annotate the selected uncertain questions.
Final Inference
Final inference for each question is performed with the newly annotated exemplars.
Considerations
- There will be an increase in inference cost and token use when employing this approach; seeing a LLM is leveraged for the uncertainty calculation.
- This study again illustrates the importance of a data centric approach to applied AI with a RLHF approach, where training data is created via human supervised process which is AI accelerated.
- This is a good example where AI is used to accelerate the human annotation process by removing noise from the data and creating training data with a clear signal.
- This approach is moving us towards a data focussed way-of-work with data discovery, data design and data development.
- As this type of implementation scales, a data productivity studio or latent space will be required to streamline the data discovery, design and development process.
Contribution
The contribution of the study is three-fold:
- A very judicious process of identifying the most valuable and relevant information sets (question and answer) for annotation. Doing this while reducing the human data-related workload via a AI accelerated process.
- The establishment of an effective set of uncertainty metrics.
- The proposed method surpasses competitive baseline models by a large margin on multiple reasoning tasks.
Baselines
It is interesting to note that this approach has four methods serving as its main baselines:
- Chain-of-thought (CoT) (Wei et al., 2022b): This method employs standard chain-of-thought prompting and offers four to eight human-written exemplars, comprising a sequence of intermediate reasoning steps.
- Self-Consistency (SC) (Wang et al., 2022c): An enhanced version of CoT, SC diverges from greedy decoding. Instead, it samples a set of reasoning paths and selects the most prevalent answer.
- Auto-CoT (Zhang et al., 2022b): This technique involves an automatic exemplar construction approach that clusters and generates rationales using zero-shot prompting (Kojima et al., 2022).
- Random-CoT: Serving as a baseline for Active-Prompt, Random-CoT follows the same annotation process. The only distinction lies in its utilisation of a random sampling method for questions from the training data during annotation, rather than employing the proposed uncertainty metrics.
More On Chain-Of-X
A number of recent papers have shown that on user instruction to do so, Large Language Models (LLMs) are capable of decomposing complex problems into a series of intermediate steps.
This basic principle was introduced by the concept of Chain-Of-Thought(CoT) prompting for the first time in 2022.
The basic premise of CoT prompting is to mirror human problem-solving methods, where we as humans decompose larger problems into smaller steps.

The LLM then addresses each sub-problem with focussed attention hence reducing the likelihood of overlooking crucial details or making wrong assumptions.
A chain of thought is a series of intermediate natural language reasoning steps that lead to the final output, and we refer to this approach as chain-of-thought prompting. ~ Source
The breakdown of tasks makes the actions of the LLM less opaque with transparency being introduced.
Areas where Chain-Of-Thought-like methodology has been introduced are:
- Chain-of-Thought Prompting
- Multi-Modal CoT
- Multi-Lingual CoT
- Chain-of-Explanation
- Chain-of-Knowledge
- Chain-of- Verification
- IR Chain-of-Thought
- LLM Guided Tree Of Thought
- Chain-Of-Note
- Least-To-Most Prompting
- Chain Of Empathy
- Supervised Chain-Of-Thought Reasoning
- Self-Consistency For Chain-Of-Thought Prompting
- Knowledge Driven Chain-Of-Thought
And more…
Previously published on Medium.






