
By now, RAG is an accepted and well established standard for addressing data relevance for in-context learning. But there are concerns regarding model behaviour when inaccurate data is retrieved.
Introduction
There are a number of developments taking place in terms of RAG.
Also, to address limitations in static and limited corpora, large-scale web searches are used to augment retrieval results.
CRAG employs a decompose-then-recompose algorithm for retrieved documents, allowing selective focus on key information and filtering out irrelevant details.
CRAG is designed to be plug-and-play and seamlessly integrate with various RAG-based approaches.
Experiments conducted during the study using four datasets covering short- and long-form generation tasks show that CRAG significantly enhances the performance of RAG-based approaches.
CRAG Overview
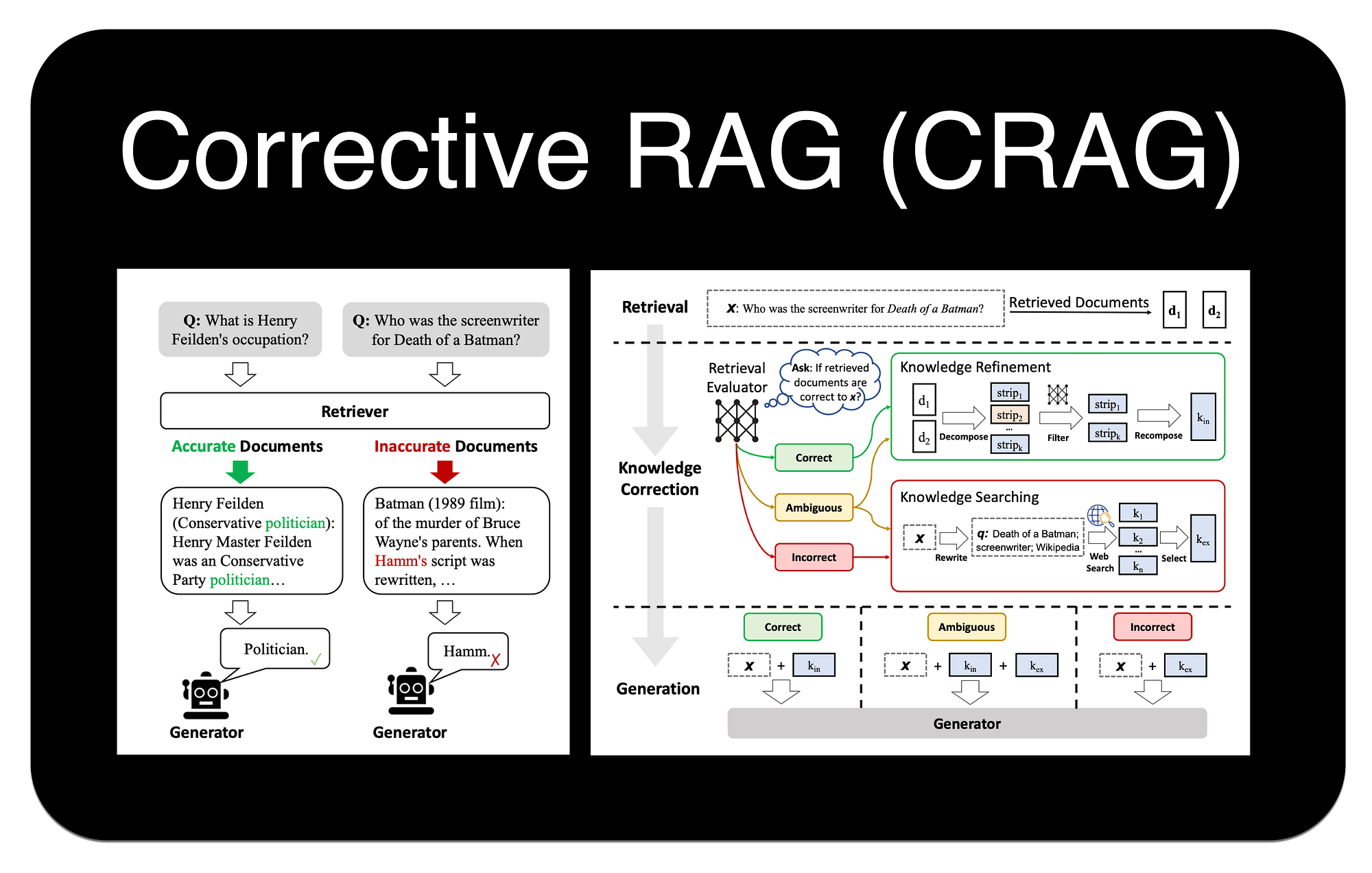
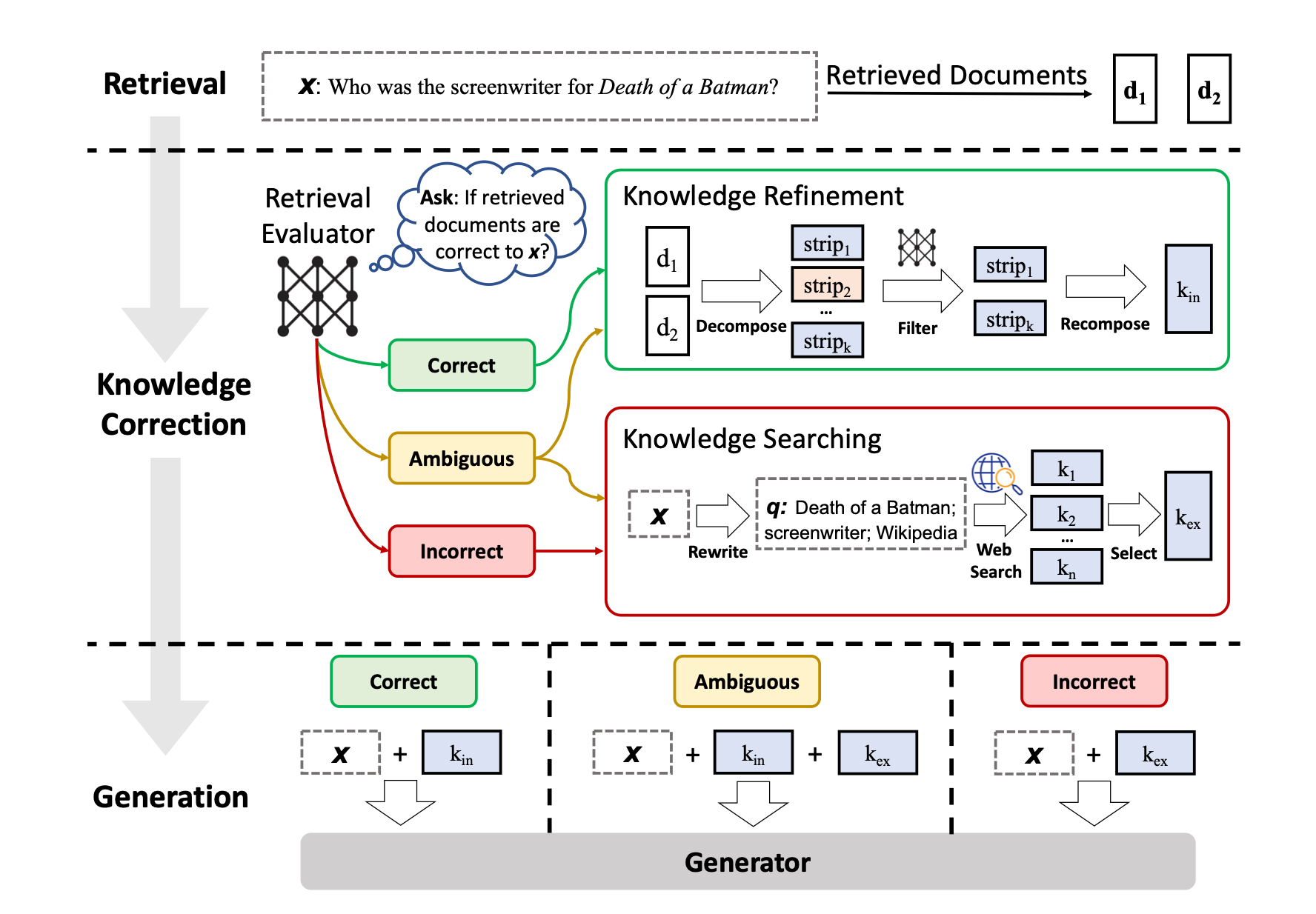
Considering the diagram below, a retrieval evaluator is constructed to evaluate the relevance of the retrieved documents to the input. An estimation of the degree of confidence is made based on which different knowledge retrieval actions of Correct, Incorrect, Ambiguous can be triggered.
The proposed method is named Corrective Retrieval-Augmented Generation (CRAG), and it is aimed to self-correct retriever results and enhance document utilisation for generation.
A lightweight retrieval evaluator is introduced to assess the overall quality of retrieved documents for a given query.
This evaluator is a crucial component in Retrieval-Augmented Generation (RAG), contributing to informative generation by reviewing and evaluating the relevance and reliability of retrieved documents.
The retrieval evaluator quantifies a confidence degree, enabling different knowledge retrieval actions such as Correct, Incorrect, Ambiguous based on the assessment.
For Incorrect and Ambiguous cases, large-scale web searches are integratedstrategically to address limitations in static and limited corpora, aiming to provide a broader and more diverse set of information.
Lastly…a decompose-then-recompose algorithm is implemented throughout the retrieval and utilisation process.
This algorithm helps eliminate redundant contexts in retrieved documents that are unhelpful for RAG, refining the information extraction process and optimising the inclusion of key insights while minimising non-essential elements.
Retrieval Evaluator
From the diagram above, it is clear that the accuracy of the retrieval evaluator plays a significant role in determining the performance of the entire system.
This algorithm ensures the refinement of retrieved information, optimising the extraction of key insights and minimising the inclusion of non-essential elements, thereby enhancing the utilisation of retrieved data.

Conclusion
This study focus on challenges faced by Retrieval-Augmented Generation (RAG) approaches when retrieval results are inaccurate, leading to the generation of incorrect knowledge by language models.
The proposed solution is something the researches named Corrective Retrieval Augmented Generation (CRAG).
The research introduces CRAG as a plug-and-play solution to enhance the robustness of generation by mitigating issues arising from inaccurate retrieval.
CRAG incorporates a retrieval evaluator designed to estimate and trigger three different actions.
The inclusion of web search and optimised knowledge utilisation operations in CRAG improves automatic self-correction and enhances the efficient utilisation of retrieved documents.
Experiments combining CRAG with standard RAG and Self-RAG showcase its adaptability to various RAG-based approaches.
The study, conducted on four datasets, illustrates CRAG’s generalisability across both short- and long-form generation tasks.






