
A multitude of Small Language Models (SLMs) are readily available as open-source resources, easily accessible through platforms like HuggingFace for downloading and offline inference.
Or local inference solutions like LM Studio, Titan ML, Jan, Ollama and more can be used.
Introduction
Before delving into the specifics of SLMs and Orca, it’s important to consider the current use cases for SLMs. These models have gained traction due to several key characteristics, including:
Natural Language Generation, Common-Sense Reasoning, Dialog Turn Control, Conversation Context Management, Natural Language Understanding and Handling Unstructured Input Data.
Considering the image below, making use of LM Studio, a quantised version of the Orca-2 13B Small Language Model (SLM) is run locally on my MacBook M2.
One of the strengths of Orca is common-sense reasoning, consider below how a complex reasoning question is posed to the Orca SLM, making use of LM Studio for local inference.

LinkedIn Feedback
Sourcing the LinkedIn community, I wanted to get a sense of what the market-feel is for SLMs…are Small Language Models used and to what extent are SLMs deemed useful.
The general consensus was that SLMs are an option when targeting a specific use-case or task. When it comes to language models, it is not necessarily about size but orchestrating multiple purpose-built models.
SLMs are also being fine-tuned to stick to a specific context and making use of RAG, hallucinations are limited.
7B models are generally considered small, because these models can run without making use of GPU when quantised.
For most enterprise implementations, there are not that many use cases where you need a behemoth model that need to be all things to all people.
In fact, enterprises largely have very carefully defined use cases in specific work flows for automation. In those cases, SLMs, with the right workflow, are definitely up for the job.
Ironically, it is when LLMs are public facing and need to be able to write Shakespeare in 5 languages and also know how to model financial data while giving you tips on how to fix your motorcycle that you need these behemoth models.
Solely based on use-cases, SLM would actually become dominant and standard, especially for running on the edge and locally.
Back To Orca
According to Microsoft, the objectives of Orca 2 are two-fold.
Firstly, the aim was to teach smaller models how to use a suite of reasoning techniques, such as:
- step-by-step processing,
- recall-then-generate,
- recall-reason-generate,
- extract-generate,
- and direct-answer methods.
Secondly, they aspired to help these models decide when to use the most effective reasoning strategy for the task at hand, allowing them to perform at their best, irrespective of their size.
The preliminary results indicate that Orca 2 significantly surpasses models of a similar size, even matching or exceeding those 5 to 10 times larger, especially on tasks that require reasoning.
This highlights the potential of endowing smaller models with better reasoning capabilities.
However Orca 2 is no exception to the phenomenon that all models are to some extent constrained by their underlying pre-trained model (while Orca 2 training could be applied to any base LLM, results reported in the study are on LLaMA-2 7B and 13B).
Orca 2 models have not undergone RLHF training for safety. Microsoft believe the same techniques applied for reasoning could also apply to aligning models for safety, with RLHF potentially improving even more.
LLMs Teaching SMLs
The training data is obtained from a more capable teacher model. Note that we can obtain the teacher’s responses through very detailed instructions and even multiple calls, depending on the task and the desired behavior of the model.
In the absence of the original instruction, which details how to approach the task, the student model will be encouraged to learn that underlying strategy as well as the reasoning capabilities it elicits.
The core principle driving the development of Orca 2 is the recognition that various tasks may require different solution approaches. These strategies range from step-by-step processing to recall-then-generate, recall-reason-generate, extract-generate, and direct answer methods.
It’s acknowledged that what works efficiently for a large model, like GPT-4, may not necessarily be optimal for a smaller one. For instance, while GPT-4 can adeptly handle complex tasks directly, a smaller model might benefit from breaking down the task into manageable steps.
Orca 2 underwent training with an extended, finely tailored synthetic dataset. This dataset is meticulously crafted to expose Orca 2 to a range of reasoning techniques, including the aforementioned methods. It also teaches the model to adapt different solution strategies based on the specific task at hand.
The training data is sourced from a more advanced teacher model.
Importantly, the teacher’s responses can be accessed through detailed instructions or even multiple iterations, tailored to the task and desired model behaviour.
In situations where the original instructions are unavailable, prompting the student model to learn both the underlying strategy and the reasoning processes it entails, becomes paramount.
Practical Reasoning Example
Consider the complex reasoning question below posed to Orca-2…
Solve the following problem by thinking step by step:
John and Mark are in a room with a ball, a basket and a box.
John puts the ball in the box, then leaves for work.
While John is away, Mark puts the ball in the basket, and then leaves for
school. They both come back together later in the day, and they do not know
what happened in the room after each of them left the room.
Where do they think the ball is?
And the detailed and correct response from the SLM:
To solve this problem step by step, let's analyze the events that occurred
while John and Mark were away:
1. John put the ball in the box before leaving for work.
2. While John was away, Mark came into the room and placed the ball in the basket.
3. Both John and Mark left the room without knowing what happened after they
put the ball in its respective location.
4. They both returned to the room together later in the day.
Since neither John nor Mark saw any changes after they put the ball in the
box and the basket, they would naturally assume that the ball is still in the
location they left it in. In this case,
John would think the ball is still in the box, and Mark would think the
ball is still in the basket.
As a result, John thinks the ball is in the box, and Mark thinks the ball is
in the basket.
Key Elements From The Study
The three key objectives from the study seem to be very much aligned with what the market requires…
Synthetic data creation: create tailored and high-quality synthetic data for small model training
Better reasoning capabilities: give smaller LMs enhanced reasoning abilities, typically found only in much larger models
Model specialisation: create specialised models that gives the model specialised capabilities or custom behaviours.
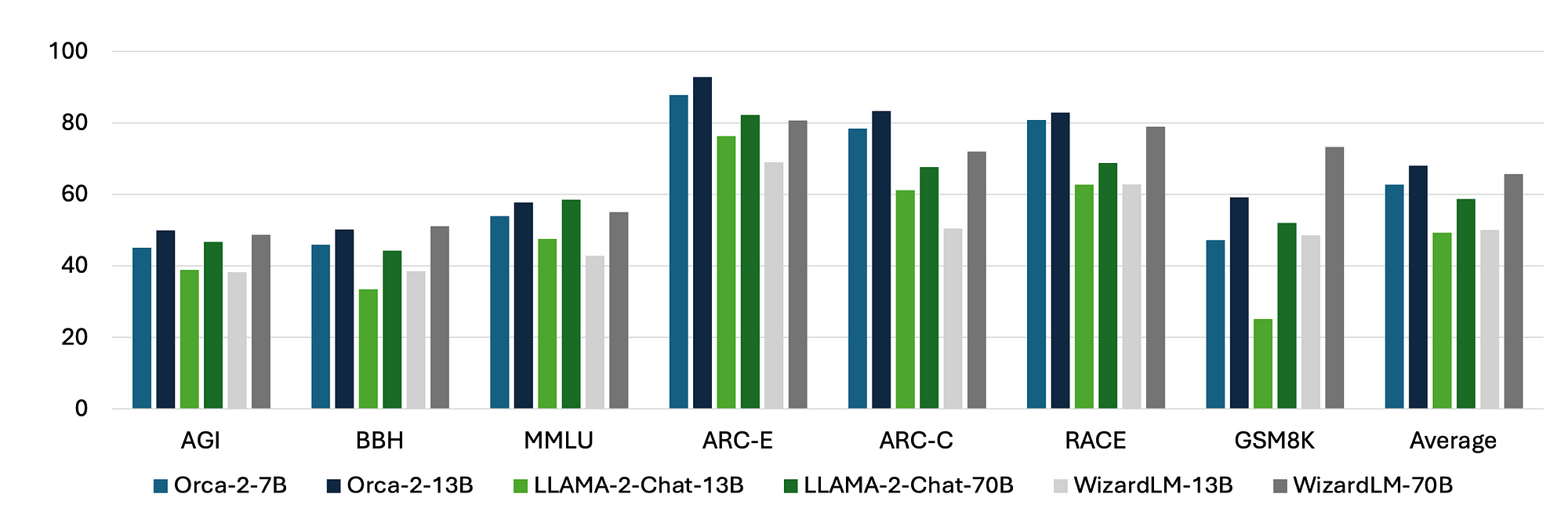
Considering the image above, which compare results of Orca 2 (7B & 13B) to LLaMA-2-Chat (13B & 70B) and WizardLM (13B & 70B) on variety of benchmarks in a 0-shot setting.
The tests covered language understanding, common sense reasoning, multi-step reasoning, math problem solving and more.
The tests show Orca 2 models match or surpass all other models including models 5–10x larger. Note that all models are using the same LLaMA-2 base models of the respective size.
Considering the performance difference between Orca-2–7B and Orca-2–13B, the delta is not that big. When it comes to deciding which version of Orca 2 to use, the difference in performance can be a valuable indication in terms of the performance / resource trade-off.
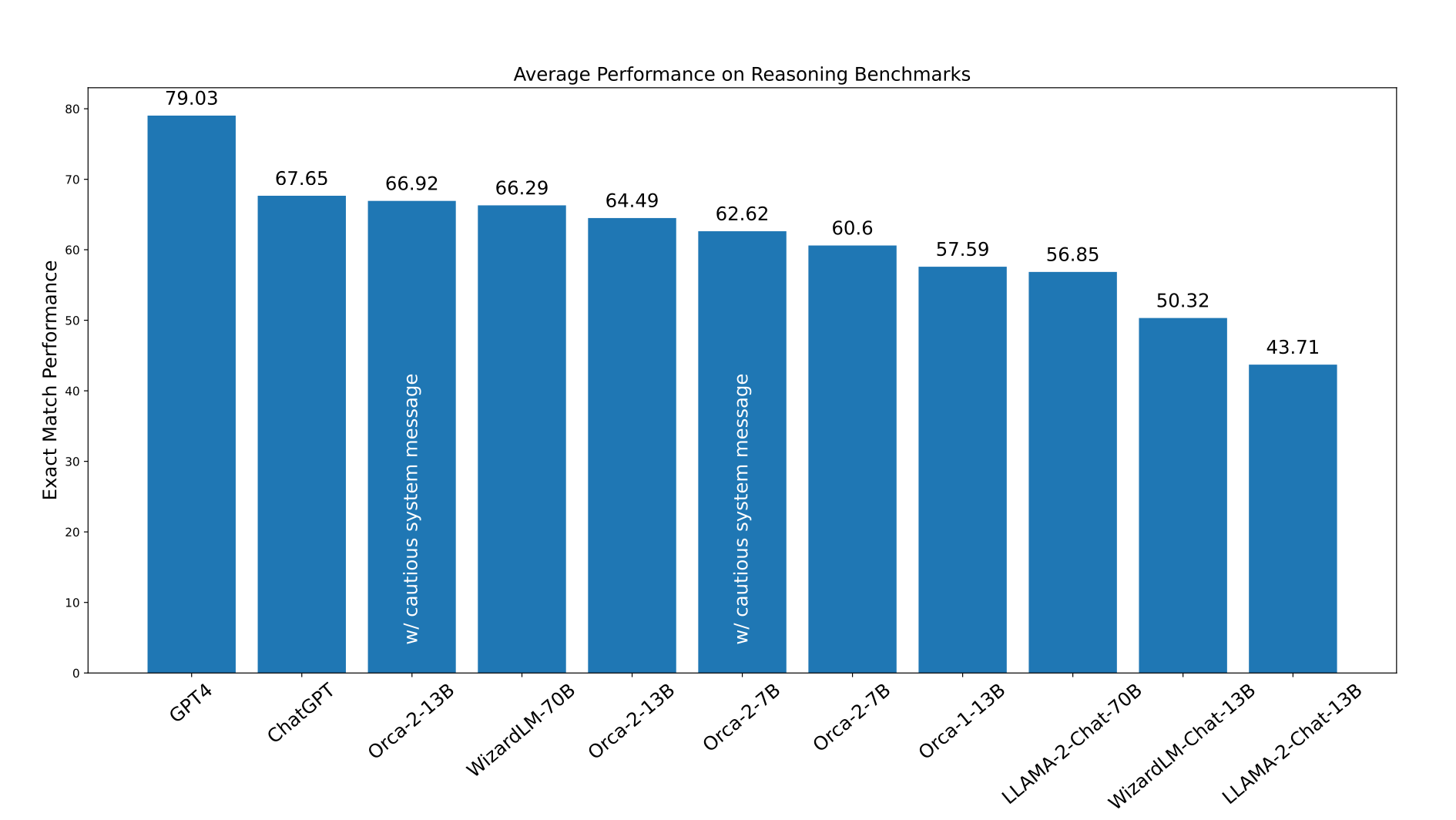
Above, the macro-average performance of different models on reasoning benchmarks.
In Closing
Microsoft’s investigation into the Orca 2 model has provided valuable insights into enhancing the reasoning capabilities of smaller language models.
Through targeted training using synthetic data, they’ve achieved performance levels that rival or even surpass those of larger models, particularly in zero-shot reasoning tasks.
Orca 2’s success can be attributed to its utilisation of diverse reasoning techniques and its ability to identify optimal solutions for different tasks.
While it does have certain limitations, including those inherent to its base models and common among other language models, Orca 2 shows considerable promise for future advancements, particularly in the realms of improved reasoning, specialisation, control, and safety for smaller models.
The strategic use of carefully curated synthetic data for post-training emerges as a pivotal strategy in driving these enhancements forward.
Microsoft’s discoveries underscore the importance of smaller models in situations where efficiency and capability must be balanced. While larger models continue to excel, Microsoft’s work with Orca 2 signifies a significant advancement in broadening the applications and deployment possibilities of language models.
Previously published on Medium.
I’m currently the Chief Evangelist @ Kore AI. I explore & write about all things at the intersection of AI & language; ranging from LLMs, Chatbots, Voicebots, Development Frameworks, Data-Centric latent spaces & more.






