
A great number of Small Language Models (SLMs) are open-sourced, easy accessible via HuggingFace for download and ready for local off-line inference.
Overview of LLM Capabilities
Before discussing SLMs, consideration needs to be given to the current use-cases for LLMs.
Large Language Models have a few key characteristics which fuelled its adoption. These include:
- Natural Language Generation
- Common-Sense Reasoning
- Dialog and Conversation Context Management
- Natural Language Understanding
- Unstructured Input Data
- Knowledge Intensive
All of these capabilities delivered in its promise, except one…the fact that LLMs are Knowledge Intensive.

While LLMs are knowledge intense, this feature has failed enterprises for the following reasons:
- LLMs have shown that it hallucinates. Hallucination can be described as the instance where an LLM generates highly succinct, plausible, believable and contextually accurate responses. But, which is factually incorrect.
- LLMs have a cut-off date for the training data of the base model. Apart from having a date where knowledge ends, LLMs do not hold all knowledge.
- LLMs do not have industry, organisational or company specific knowledge and information.
- Updating an LLM would require fine-tuning of the base model, which requires data preparation, cost, testing, etc. This introduces a non-gradient opaque approach of data delivery to LLMs.
Retrieval-Augmented Generation (RAG)
The solution which was introduce to solve for this is RAG.
RAG serves as an equaliser when it comes to Small Language Models (SLMs). RAG supplements for the lack of knowledge intensive capabilities within SLMs.
Apart from the lack of some Knowledge Intensive features, SLMs are capable of the other five aspects mentioned above.
Microsoft Phi-2
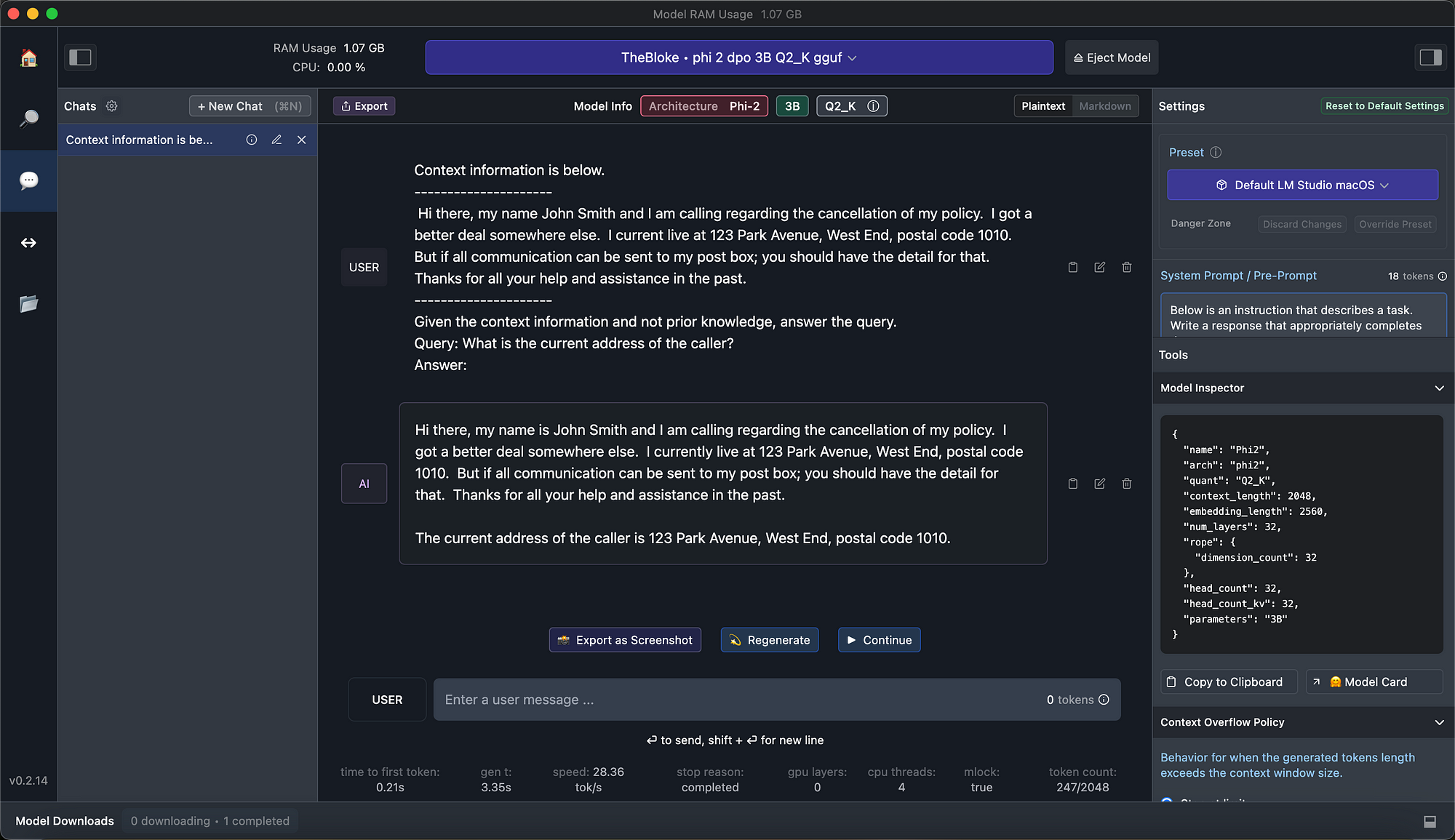
Microsoft recently open-sourced their Phi-2 model, making use of LM Studio, I could download and run the SLM locally on my MacBook. Below the model detail:
{
"name": "Phi2",
"arch": "phi2",
"quant": "Q2_K",
"context_length": 2048,
"embedding_length": 2560,
"num_layers": 32,
"rope": {
"dimension_count": 32
},
"head_count": 32,
"head_count_kv": 32,
"parameters": "3B"
}
Here is the LM Studio UI:
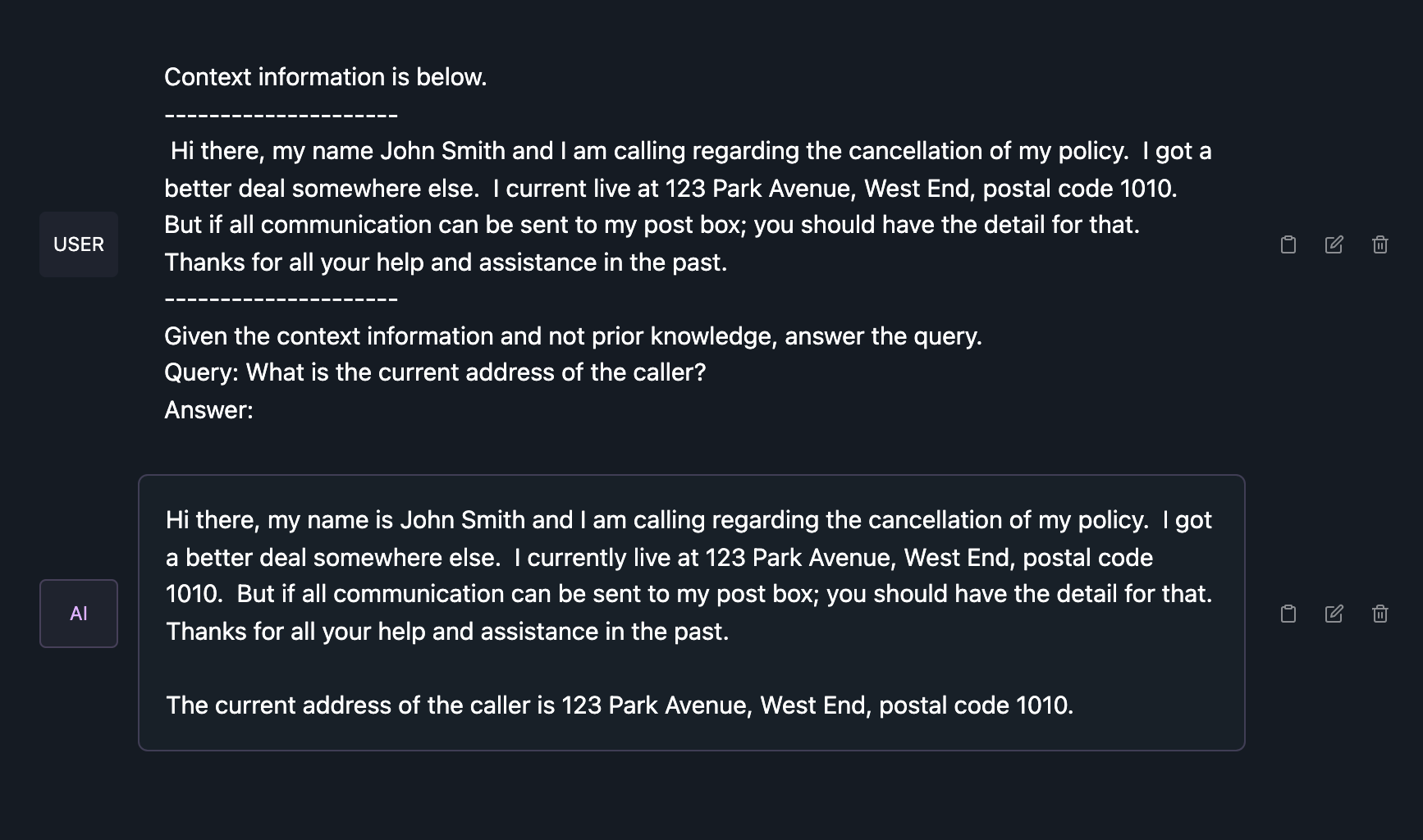
I created a typical customer care scenario, where a user will have a customer care query. This customer input serves as the context.
I then asked the model to extract the current address of the caller, nested within the context.
The SML was able to extract the address form the text.
Query: Extract all the address from the context?
Response: The details for the address are:
123 Park Ave, West End Suburb (postal code 1010).
And below the Phi-2 SLM is used in a RAG implementation, you can see the context information is supplied. And the SLM is instructed to make use of context and not access any prior knowledge.
Then a contextually relevant question is asked and the question is answered comprehensively as seen below.
If the SLM Phi-2 is asked a NLU related question:
Extract the entities from the following sentence:
"I need to book a flight from Bonn to Amsterdam for four people and
two children for next week Monday."
With the response:
[Entity] I need to book a [flight] from [Bonn] to [Amsterdam] for [four people] and [two children].
The question:
What is the number of people in total?
And the response:
The count for "people" is six.
Accelerated Generative AI Adoption
LLMs are only accessible via the three options shown below in the image.
There are a number of LLM-based User Interfaces, like HuggingChat, Cohere Coral, ChatGPT and others. These UIs are a conversational interface where in some instances the UI learns the specific user’s preferences etc. Cohere Coral allows for the upload of documents and data to serve as a contextual reference.
LLM API’s are the most popular way for organisations and enterprises to make use of LLMs. Commercial offerings, as listed in the image below are numerous. LLM API’s are the easiest way to build Generative Apps, but it comes with challenges of cost, data privacy, inference latency, rate limits, catastrophic forgetting, model drift and more.
There are a number of open-sourced, free to use raw models, but these require specialised knowledge to implement and run. Together with hosting costs which will scale with adoption.
Local and private hosting of SLMs which are fit for purpose solves most of these challenges.
In the image below is a local inference server I downloaded and installed locally. From this local inference server, any model on HuggingFace can be referenced, downloaded and run locally, off-line, etc.
In the example below I’m making use of the TinyLlama/TinyLlama-1.1B-Chat-v1.0 model. You can see the system prompt is defined, with a user request.
This NLU related question to extract the key words are answered comprehensively and accurately.
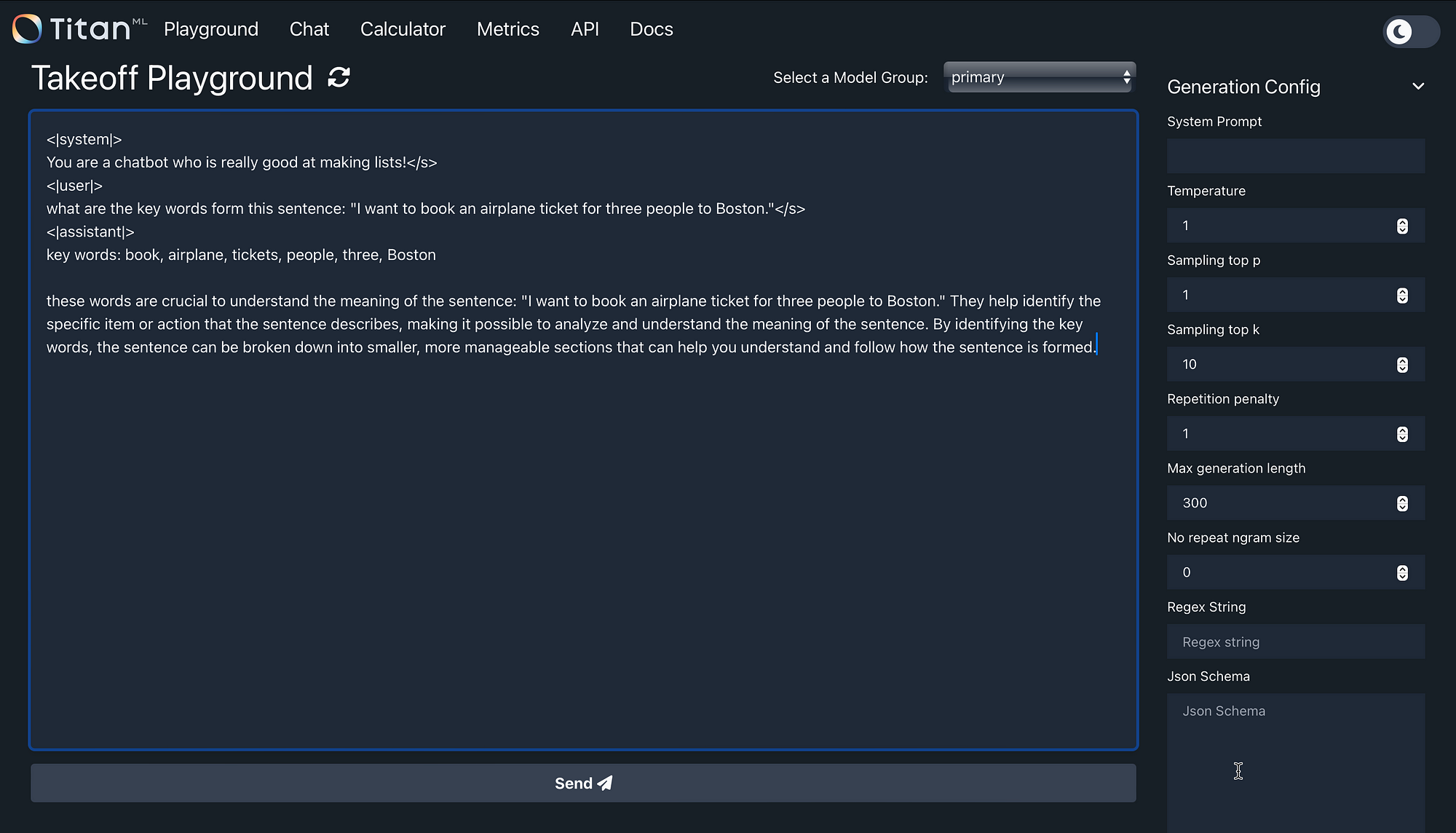
Local Install
As mentioned earlier, the most common impediments to the adoption of LLMs are inference latency, token usage cost, fine-tuning cost, data privacy and protection.
Together with proven phenomenons like LLM Drift and Catastrophic Forgetting. Local and private hosting of SLMs which are fit for purpose solves most of these challenges.
Data Protection
SLMs do not only merely simplify the process of self-hosting models.
In principle, being able to self-host any model allows for end-to-end management of the flow of data. Applications can be created to run offline, without all the dependancies of services and applications being tethered to a LLM, often without any regional or geographic representation.
When a private instance of a model is hosted, enterprises can ensure that private data is not used for training of the model.
Enterprise Considerations
The biggest consideration is model cost; with a whole host of models, both LLMs and SLMs being open-sourced, self-hosting these models become economically viable. And due to the size and efficiency of SLMs, the impediments of self-hosting are much lower.
Impediments To SLM Adoption
First of all, experimentation and use-case specific considerations will determine who will be using SLMs and derive benefit.
The biggest impediment to the adoption of SLMs is the degree to which SLMs are made available via commercial APIs.
However, as I have shown earlier in this article, there are a number of quantisation software platforms which allow laymen to download and run open-sourced SLMs in their local CPU environment. Without any specialised hardware, know-how, or other computing resources.
The Future of SLMs & Generative AI
Access to Generative AI will be democratised and an increasing number of applications will make use of generative AI and conversational user interfaces.
Take NLU as an example, there are a number of open-sourced NLU software solutions. NLU engines can be locally installed and run, similarly SLMs offer the same advantage.
With the introduction of RAG, LLMs are not primarily used for their knowledge intensive nature but for tasks like dialog management, common-sense reasoning and natural language generation. These are all tasks SLMs excel at, and hence the cost, technical and accessibility advantages will play a big role.
From a consumer perspective, the technology will be transparent.
However, the user experience will improve considerably. Conversational user experience and generative AI based applications can be implemented on smaller devices, and run off-line, contributing to accessibility, resilience and ubiquitous adoption.
Model orchestration will become a de facto approach in the future, where the model best suited for the use-case is implemented.
LLMs are knowledge-intensive in nature, hence general knowledge questions and reasoning can be leveraged. LLMs are capable of ever increasing context windows.
LLMs are also morphing into what some refer to as Foundation Models or Multi-Modal Models with image and audio capabilities.
Should these features be a requirement for a use-case, then LLMs are appropriate. But there will be several other use-cases where a SLM will suffice.
Previously published on Medium.






