
A recent direction in RAG architecture is establishing wider context via a process of orchestration and chains over multiple documents.

Here are a few general trends I have observed of late…
Considering the development of the Large Language Model (LLM) application ecosystem, LlamaIndex and LangChain are really at the forefront of establishing de facto application frameworks and standards.
And even if organisations don’t want to use their frameworks, studying their methods lends much insight into how the ecosystem is developing.
Here is a short list of recent market developments and shifts:
- For both gradient and non-gradient approaches a data centric approach is becoming increasingly important. Especially with the importance of in-context learning and contextual reference data.
- Human annotated data, RLHF, data-centric approaches etc. are receiving more attention. And various ways in which human supervision of input and output data can be optimised with introducing efficiencies.
- Prompt Pipelines are receiving more attention; building a process of data retrieval, synthesising data and other text related tasks.
- RAG frameworks are expanding with the introduction of RAG pipelines, multi-document retrieval and Agentic RAG…
- Agents were seen as unpredictable and demanding too much overhead in terms of inference latency and cost. Of late multi-layered and multi-agent RAG implementations have seen the light, with an approach LlamaIndex refers to as Agentic RAG.
Intro to MultiHop-RAG
- Retrieval-augmented generation (RAG) enhances large language models (LLMs) by retrieving relevant contextual knowledge. Thus addressing LLM hallucinations, and improving response quality by leveraging in-context learning (ICL).
- Existing RAG systems face challenges in answering multi-hop queries, requiring retrieval and reasoning over multiple pieces of evidence. One can think of this as a chaining process, where relevant information is retrieved over multiple documents. And subsequently these pieces of relevant information is synthesised into one coherent and succinct answer.
- The research paper introduces a new benchmarking dataset, MultiHop-RAG, focused on multi-hop queries, including a knowledge base, queries,ground-truth answers, and supporting evidence.
- Experiments reveal that existing RAG methods perform unsatisfactory in handling multi-hop queries.
- The MultiHop-RAG research will serve as a valuable reference resource for the community in developing effective RAG systems, promoting the greater adoption of LLMs in practice.
The MultiHop-RAG & implemented RAG system are publicly available.
Complex Question Answering
Considering the two questions below, these are more complex questions which span over a number of companies in the first instance. And in the example for the second question, a period of time is given to which the data needs to be relevant.
Which company among Google, Apple, and Nvidia reported the largest profit margins in their third-quarter reports for 2023?
How does Apple’s sales trend look over the past three years?
From these two example questions, it is clear that elements like a knowledge base, ground-truth answers, supporting evidence, and more are required to accurately answer these questions.
These queries require evidence from multiple documents to formulate an answer. Again, this approach strongly reminds of LlamaIndex’s Agentic RAG approach.
Considering the table below, an example of a multi-hop query is given. The sources are defined, with the claim, and a bridge-topic together with a bridge-entity.
The query is shown, with the final answer.
I have often referred to inspectability and observability as one of the big advantages of a non-gradient approach like RAG. The table below is a very good case in point, where the simple answer of “yes” can be traced back.

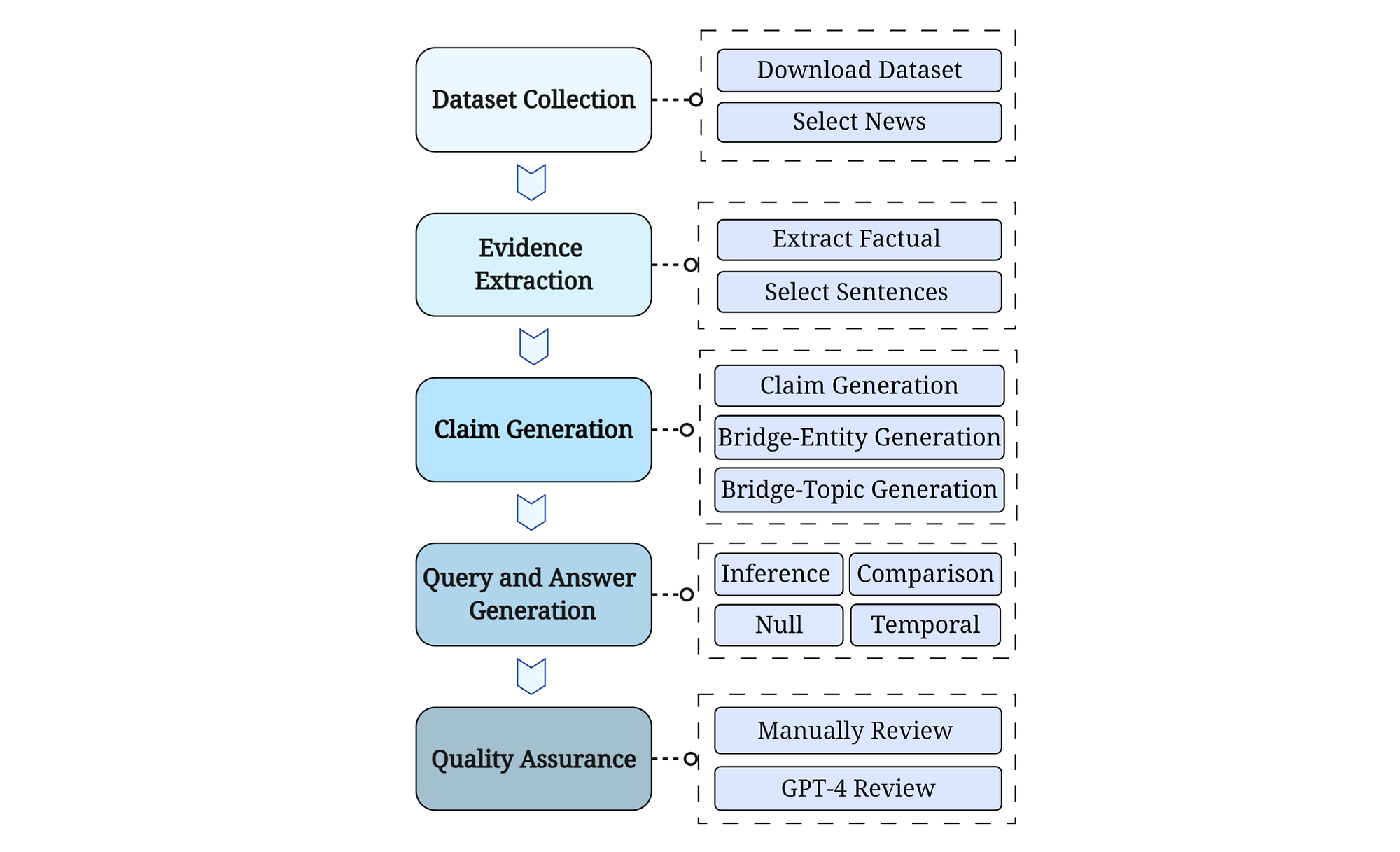
MultiHop-RAG Construction Pipeline
The diagram below shows the MultiHop-RAG Pipeline, from the data collection step, to the final step of quality assurance.
Dataset Collection
The study utilised the mediastack API to download a diverse news dataset covering multiple English-language categories such as entertainment, business, sports, technology, health, and science.
To simulate real-world Retrieval-augmented generation (RAG) scenarios, the selected news articles span from September 26, 2023, to December 26, 2023, extending beyond the knowledge cutoff of widely-used LLMs like ChatGPT and LLaMA. This timeframe ensures potential divergence between the knowledge base data and the LLMs’ training data.
Evidence Extraction
A trained language model was used to extract factual or opinion sentences from each news article. These factual sentences serve as evidence for addressing multi-hop queries. The selection process involves retaining articles with evidence containing overlapping keywords with other articles, facilitating the creation of multi-hop queries with answers drawn from multiple sources.
Chain Generation
GPT-4 was used to paraphrase the evidence, which are referred to as claims, given the original evidence and its context.
Query & Anser Generation
The bridge-entity or bridge-topic are used to generate multi-hop queries.
Quality Assurance
To ensure dataset quality, the study employed two approaches.
- A subset sample of generated multi-hop queries, their associated evidence sets, and final answers which undergo a manual review, revealing a high level of accuracy and data quality.
- GPT-4 is utilised to assess each dataset example based on specific criteria, including the requirement for the generated query to utilise all provided evidence.
Limitations
The study acknowledges several limitations for potential improvement in future research.
- The ground truth answers are constrained to simple responses, limiting evaluation to straightforward accuracy metrics. Future research could explore the inclusion of free-text answers and employ more sophisticated metrics for assessing generation quality.
- The current dataset restricts supporting evidence for a query to a maximum of four pieces, suggesting the possibility of extending it to include queries requiring more evidence.
- The study states that the experiments use a basic RAG framework with LlamaIndex. And that future work could involve evaluating multi-hop queries using more advanced RAG frameworks or LLM-agent frameworks.
- LlamaIndex recently released an advanced RAG framework implementation; referred to by LlamaIndex as Agentic Rag.
Previously published in Medium.






