
Introduction
These two approaches are often pitted against each other as to which one is the best.
RAG is known for improving accuracy via in-context learning and is very affective where context is important.
RAG is easier to implement and often serves as a first foray into implementing LLMs due to RAG’s inspectability, observability and not being as opaque as fine-tuning.
With RAG the input token size increases with the prompt size, and the study found that the output token size tend to be more verbose and harder to steer.
The study found that fine-tuning offers a precise, succinct output that is attuned to brevity. It is highly effective and presents opportunities to learn new skills in a specific domain.
But the initial cost is high in terms of data preparation and running the fine-tuning process.
But when it comes to usage, fine-tuning necessitates minimal input token size, making it a more efficient option for handling large data sets.
It is evident that additional cost will have to be incurred somewhere; with RAG it is during model inference and not upfront. With fine-tuning the cost upfront is higher, with lower inference cost.
Using RAG & Fine-Tuning In Conjunction
This research propose a pipeline for using both fine-tuning and RAG.
This study made use of Q&A generation, which creates question and answer pairs based on the information available.
RAG uses it as a knowledge source.
The generated data is then refined and used to fine-tune several models while their quality is evaluated using a combination of proposed metrics.
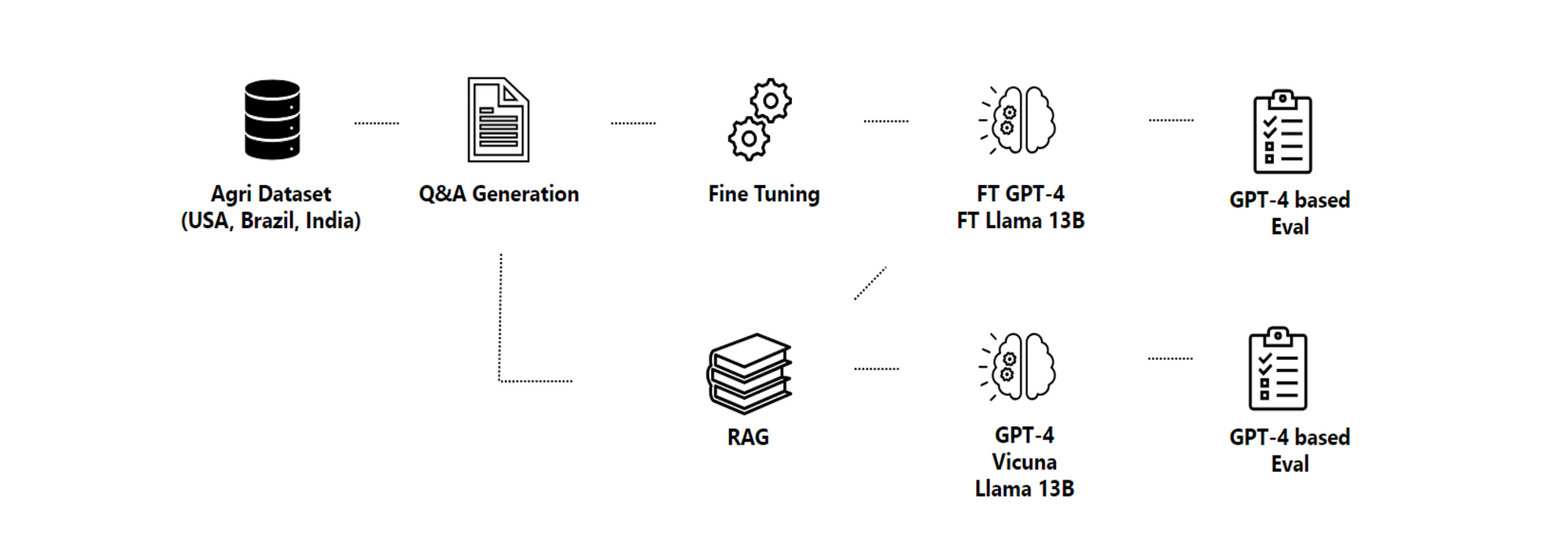
In the image below, the methodology pipeline is seen…
- Domain-specific datasets are collected, and the
- Content and structure of the documents are extracted.
- This information is then used for the Q&A generation step.
- Synthesised question-answer pairs are used to fine-tune the LLMs.
Models are evaluated with and without RAG under different GPT-4-based metrics.
Accuracy
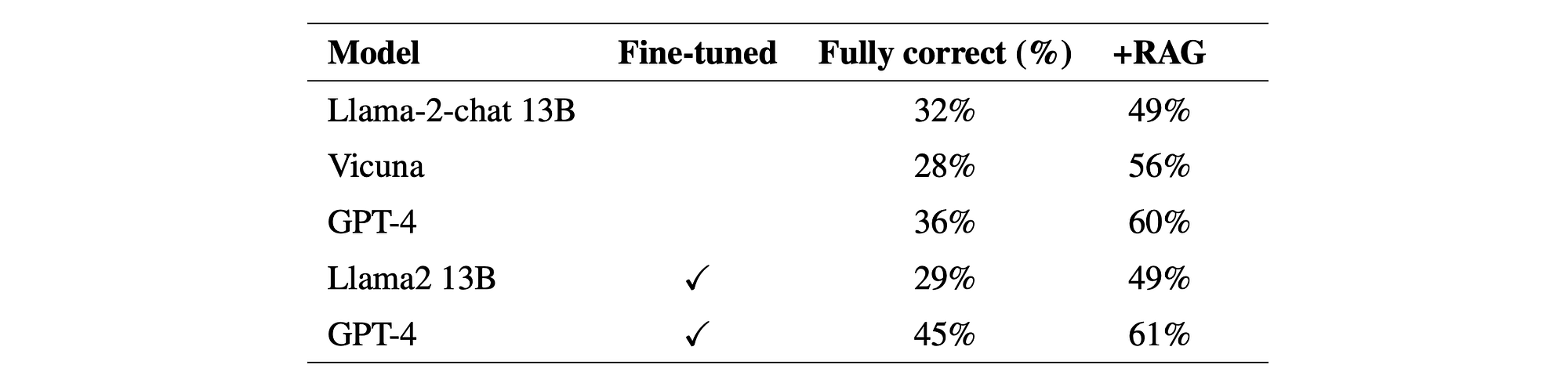
The table below compares the accuracy from tests with no fine-tuning, with fine-tuning, and with RAG added. Considering GPT-4, the accuracy goes from 75% to 81% after being fine-tuned on domain specific information.
And then when RAG is added, the accuracy in the case of GPT-4 goes up to 86%.

The table shows the percentage of answers that were fully correct, for base and fine-tuned models with and without RAG. Again just considering GPT-4, the leap in accuracy with fine-tuning is almost 10%, with RAG adding 16% accuracy.
Finally
The table below is a good summary of comparing different aspects of the model to RAG and fine-tuning.
It is evident that additional cost will have to be incurred somewhere; with RAG it is during model inference and not upfront. With fine-tuning the cost upfront is higher, with lower inference cost.

The study also found that in their tests, GPT-4 consistently outperformed other models. But that the costs associated with fine-tuning and inference cannot be ignored and are an important trade off to consider.
Both RAG and fine-tuning prove to be effective techniques, with their appropriateness depending upon the specific application, the characteristics and scale of the dataset, and the resources allocated for model development.
Previously published on Medium.






