
In the recent past I have been observing and describing current LLM-related technologies and trends. In this article I’m taking a step back to present an updated overview of the current Large Language Model (LLM) landscape.
Introduction
The image above shows the ripples caused by the advent of LLMs which can be divided into six bands or zones. As these ripples extend, there are requirements and opportunities for products and services.
Some of these opportunities have been discovered, some are yet to be discovered. I would argue that the danger of being superseded as a product is greater in Zone 6 as apposed to Zone 5.
Zone 5 offers a bigger opportunity for differentiation, substantial built-in intellectual property and stellar UX enabling enterprises to leverage the power of LLMs. Exciting developments in Zone 5 include quantisation, Small Language Models, model gardens/hubs and data centric tooling.
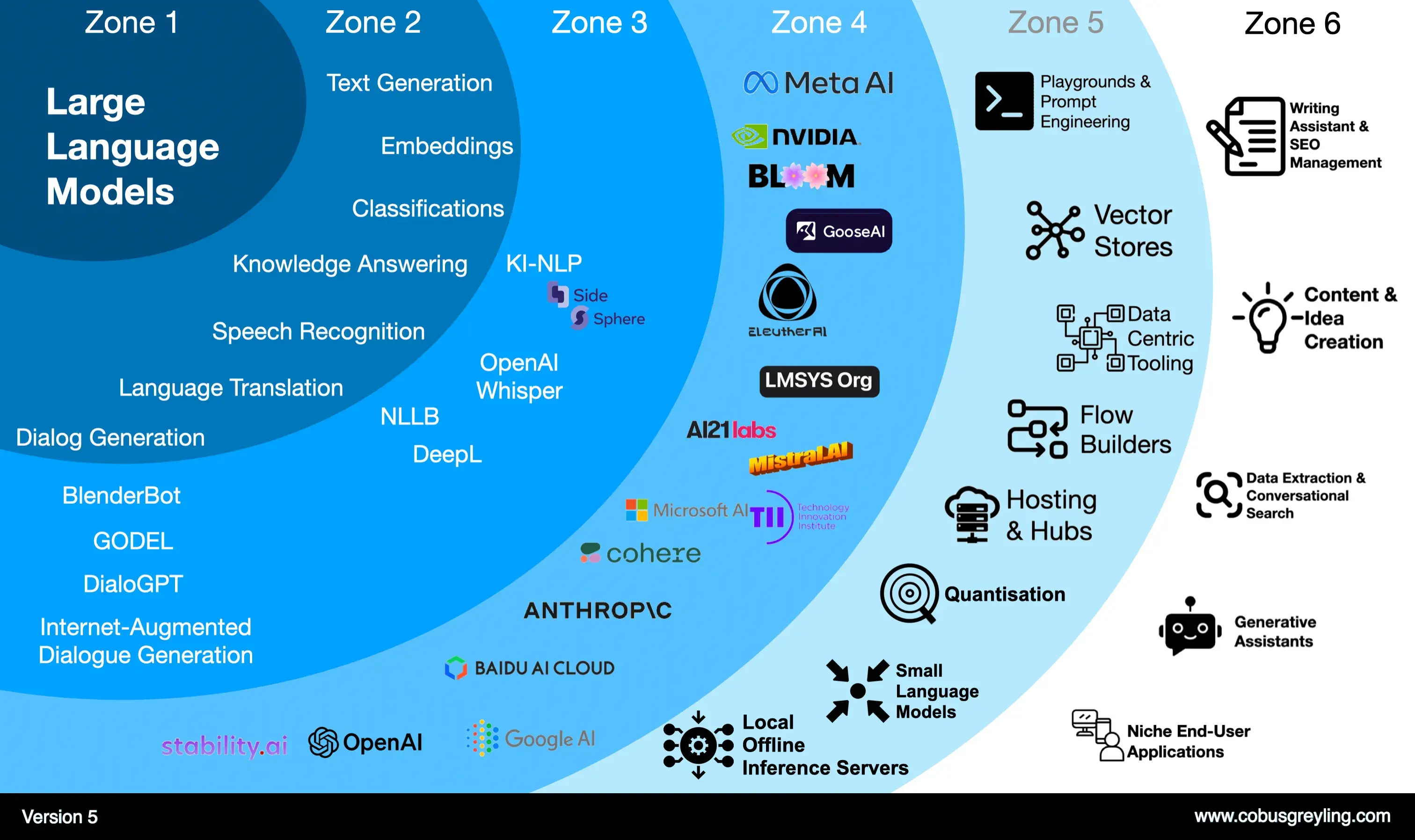
Zone 1 — Available Large Language Models
Considering LLMs, in essence LLMs are language bound, however, multi-modal models or multi-modality have been introduced in terms of images, audio and more. This shift gave rise to a more generic term being used, namely Foundation Models.
Apart from increased modalities, there has been model diversification from the large commercial providers, offering multiple models which are more task specific. There has also been a slew of open-sourced models made available. The availability and performance of open-sourced models have given rise to easy, no-code hosting options, where users can select and deploy models via a no-code fashion.
New prompting techniques have illustrated how models performance can be enhanced and how the market are moving towards a scenario where data discovery, data design, data development and data delivery can be leveraged to achieve this level of model-autonomy.
Zone 2 — General Use-Cases
With the advent of large language models, functionality was more segmented…models were trained for specific tasks. Models Sphere & Side focussed on Knowledge Answering; something Meta called KI-NLP. Models like DialoGPT, GODEL, BlenderBot and others focussed on dialog management.
There were models focussing on language translation, specific languages, etc.
Recent developments in LLMs followed an approach where models incorporate these traits, with one model consolidating most, if not all of these functions. Add to this astounding performance can be extracted using different prompting techniques.
The main implementations of LLMs are listed here, with text generation encompassing tasks like summarisation, rewriting, key-word extraction and more.
Text analysis and RAG are becoming increasingly important, and embeddings are vital for these type of implementations.
Speech recognition, also known as ASR is the process of converting audio speech into text. The accuracy of any ASR process can easily be measured via a method called Word Error Rate (WER). ASR opens up vast amounts of recorded language data for LLM training and use.
Notable shifts in this zone are:
- Knowledge answering and Knowledge Intensive NLP (KI-NLP) approaches are superseded by RAG Prompt Engineering at inference.
- LLM functionality consists of a few elements: dialog & context management, logic & reasoning, unstructured input and output, natural language generation and knowledge intense base-model. All of these elements are leveraged extensively, except the knowledge intensive nature of LLMs.
- The base knowledge intensive nature of the LLMs are being replaced by In-Context Learning strategies at inference. Most notable here is RAG as a standard that most technology providers are standardising on.
- Dialog generation was spearheaded by developments like GODEL and DialoGPT. These have been superseded by specific implementations like ChatGPT, HuggingChat and Cohere Coral. Also by prompt engineering approaches where few-shot training is used with the dialog context presented in the prompt.
Zone 3 — Specific Implementations
A few specific-use models are listed in this zone. As mentioned before, models have become less use-case specific, and models have started to incorporate multiple if not all of these elements in one model.
Zone 4 — Models
The most notable Large Language Model suppliers are listed here. Most of the LLMs have inbuilt knowledge and functionality including human language translation, capability of interpreting and writing code, dialog and contextual management via prompt engineering.
Some of these models suppliers make APIs available, some models are open-sourced and are freely available to use. The only impediment is hosting, managing and managing the APIs.
Zone 5 — Foundation Tooling
This sector considers tooling to harness the power of LLMs, including vector stores, playgrounds and prompt engineering tools. Hosting like HuggingFace enables no-code interaction via model cards and simple inference APIs.
Listed in this zone is the idea of data-centric tooling which focusses on repeatable, high value use of LLMs.
Recent additions to this area is local off-line inference servers, quantisation, and small language models.
The market opportunity in this area is creating foundation tooling which will address a future need for data delivery, data discovery, data design and data development.
Zone 6 — End User UIs
On the periphery, there is a whole host of applications which focus on flow building, idea generation, content and writing assistants. These products focus on UX and adding varying degrees of value between LLMs and the user experience.
Previously published on Medium.






