
Introduction
When any organisation is building an end-user facing GUI for a LLM-based personal assistant, this research is invaluable.
Users have different expectations in terms of detailed, factual and professional responses, across different intents.
Understanding the user intent is important to the LLM in knowing how to respond.
LLMs fail most in solving problems and creativity; both are difficult intents to quantify and gauge to understand what the user expectation is.
It seems like a level of disambiguation will work well for more creative and problem solving tasks. Where the dialog turn is introduced from the LLM to seek clarification from the user.
Classifying user intent is still important; perhaps not from a run-time/inference-time perspective for the time being. But classifying user intent over time will add to the success of the assistant.
With Large Language Models (LLMs) the focus has been two-fold; the first has been on various methods and approaches to benchmarking LLMs.
The second focus was on how to enhance the intelligence of LLMs and the most effective way of delivering data to the model.
The gap identified by a recent study is the user experience (UX) portion; how are users interacting, using and experiencing LLMs.
This study focuses on four key aspects:
- Understanding user intents,
- Scrutinising user experiences,
- Addressing major user concerns about current LLM services, and
- Outlining future research paths for enhancing human-AI collaborations.
The study develops a taxonomy of seven user intents in LLM interactions based on real-world interaction logs and human verification.
Key Findings
- LLM interfaces are used at least weekly by around 80% of surveyed participants.
- Seven user intents were identified.
- Top three usage scenarios: Text Assistant, Information Retrieval, and Problem Solving.
- Subjective usage includes Seeking Creativity and Asking for Advice, are also common intents but may have been overlooked by previous research.
- User studies verify that LLMs are highly effective in text manipulation tasks.
- Subjective areas, such as Creativity, require further advances to boost user satisfaction.
- User Expectations vary greatly across scenarios, which might not always align with the current evaluation standards.
- Users anticipate specific tool utilisation based on intent, underscoring the necessity of fine-grained scenario segmentation based on user intent.
- Personalisation functionality is valued across all subjective usage of LLMs (Seek Creativity, Ask for Advice, and Leisure).
- The user concerns and desired improvements are mainly two parts: model capability and trustworthiness.
Four Research Question
The four research questions of this study are:
- What are the primary user intents for engaging with conversational interfaces powered by large language models (LLMs)?
- How do users perceive their experience when interacting with current LLM services in real-world settings?
- What key concerns do users have for using large language models?
- What are future directions in building user centred large language models for better human-AI collaboration?
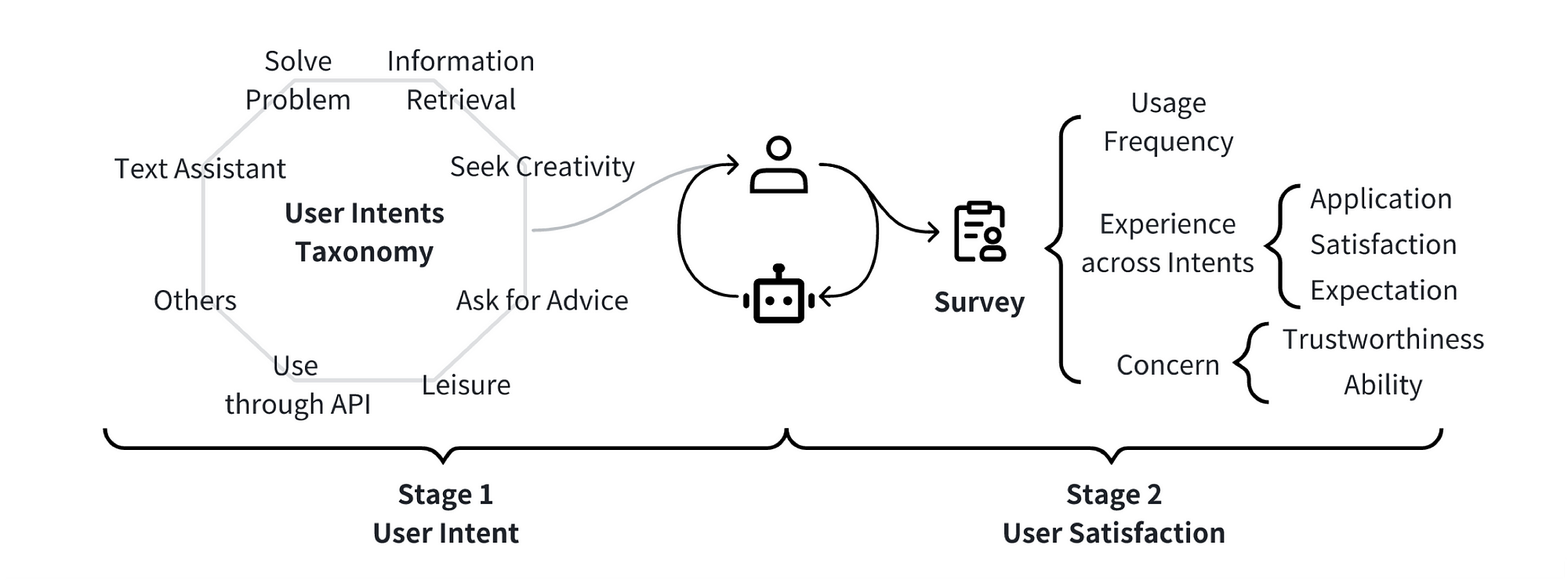
Considering the image above, what I really found valuable are the user intents identified by the study. Together with 11 findings on usage frequency, user experience, and concerns with LLMs.
And finally 6 research directions for future human-AI collaboration studies are highlighted.
User Engagement With LLMs
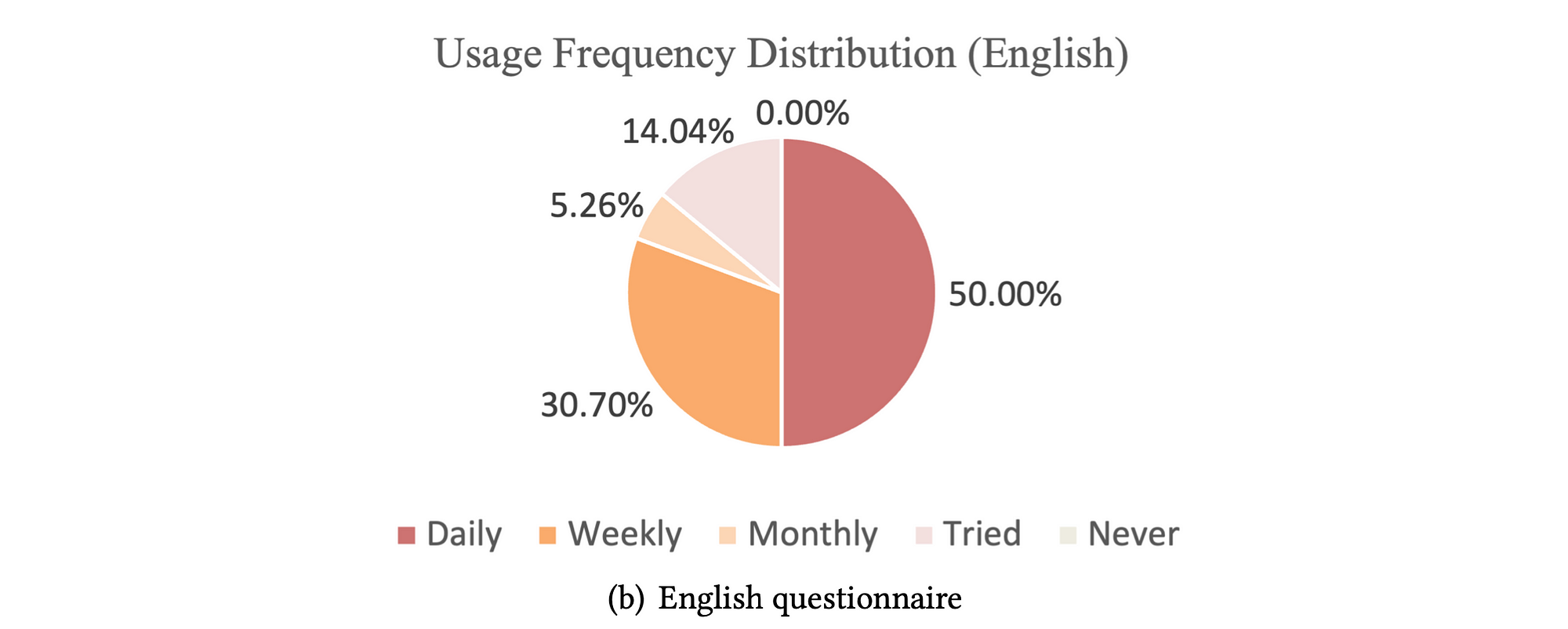
From the participants surveyed, hals interacting with LLMs on a daily basis and a large percentage of users interacts with LLMs on a weekly basis.
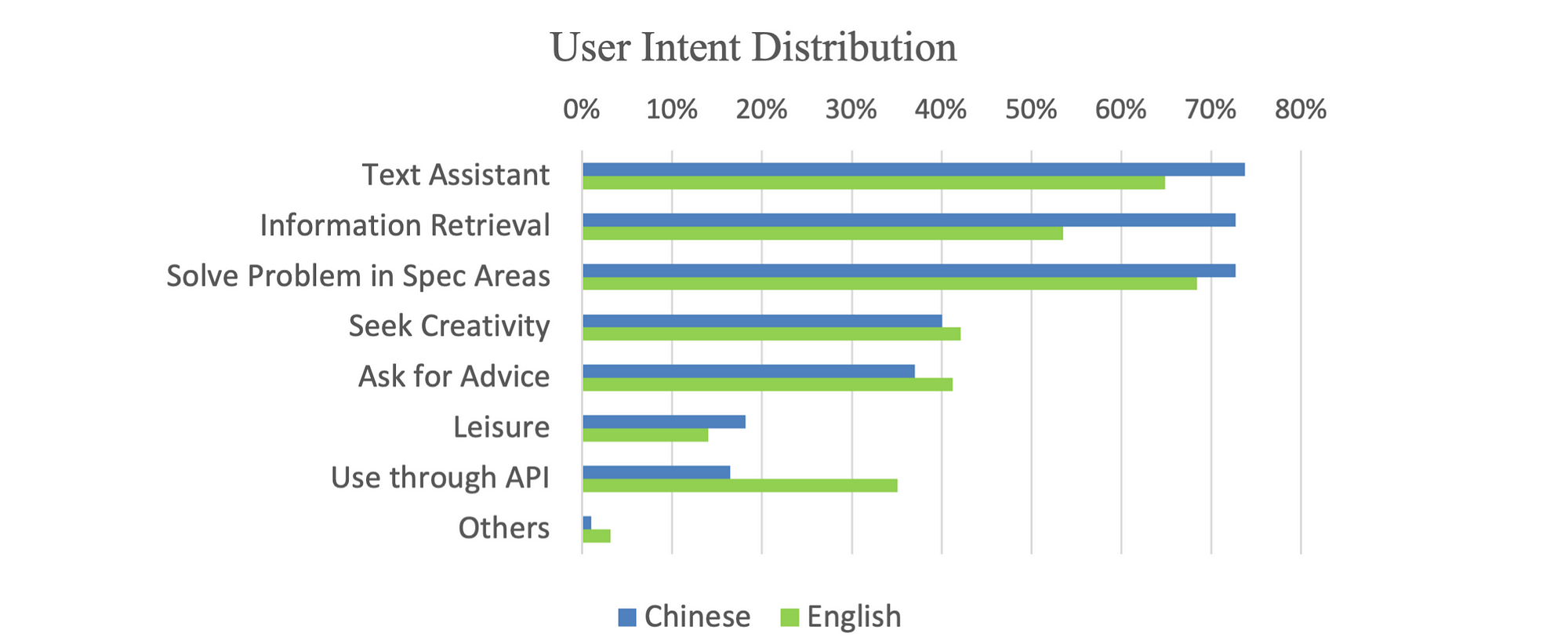
The graph below shows the users intent distribution. The top three intents are expected, using the LLM as a text assistant, information retrieval and for solving problems.
What I find interesting is the large extent to which LLMs are used for creativity and giving advice.
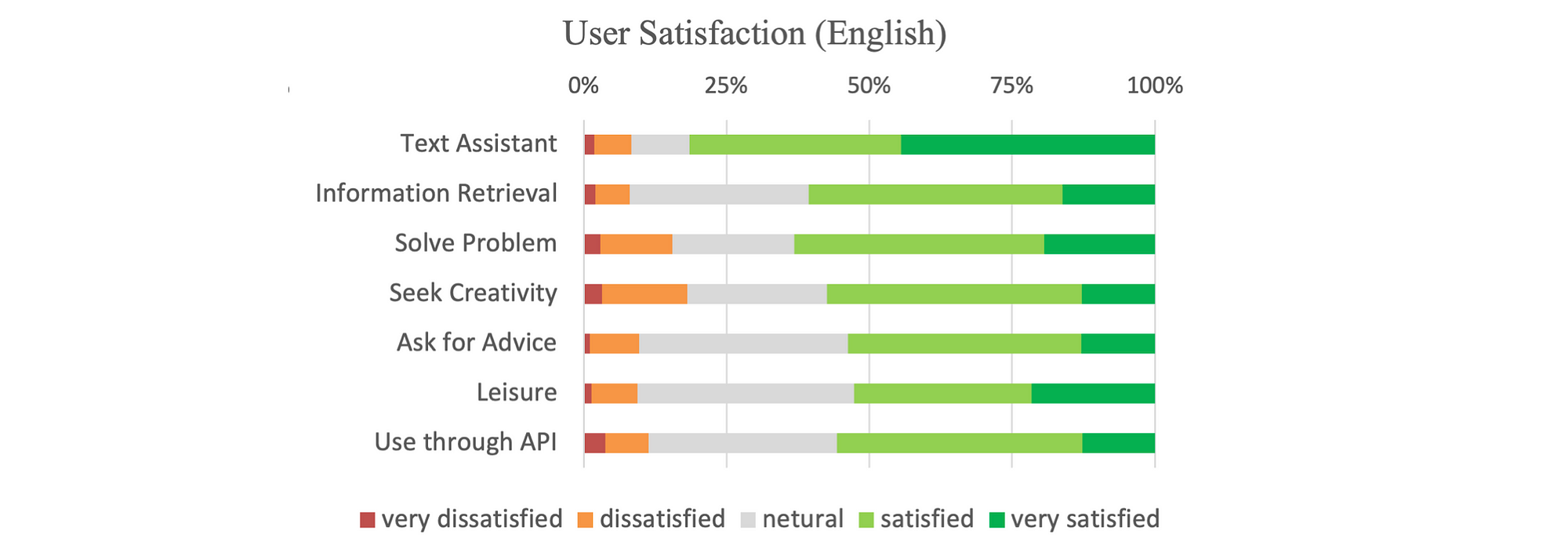
Text Assistant elicited the highest satisfaction rates , with over 80% reporting being satisfied or very satisfied. This suggests that this conversational service is well-suited to language-based assistance tasks.
Seeking Creativity use cases had the highest negative feedback. Around 18% of English users reported not being satisfied. This indicates that current LLMs have room for improvement when generating novel or imaginative outputs.
Below, User Usage Percentage and Rating across Intents. Usage percentage represents the ratio of users who used LLMs under each intent.
User ratings are calculated by assigning 1–5 to “very dissatisfied” — “very satisfied” and then averaging the scores of the users who participated under these intentions.
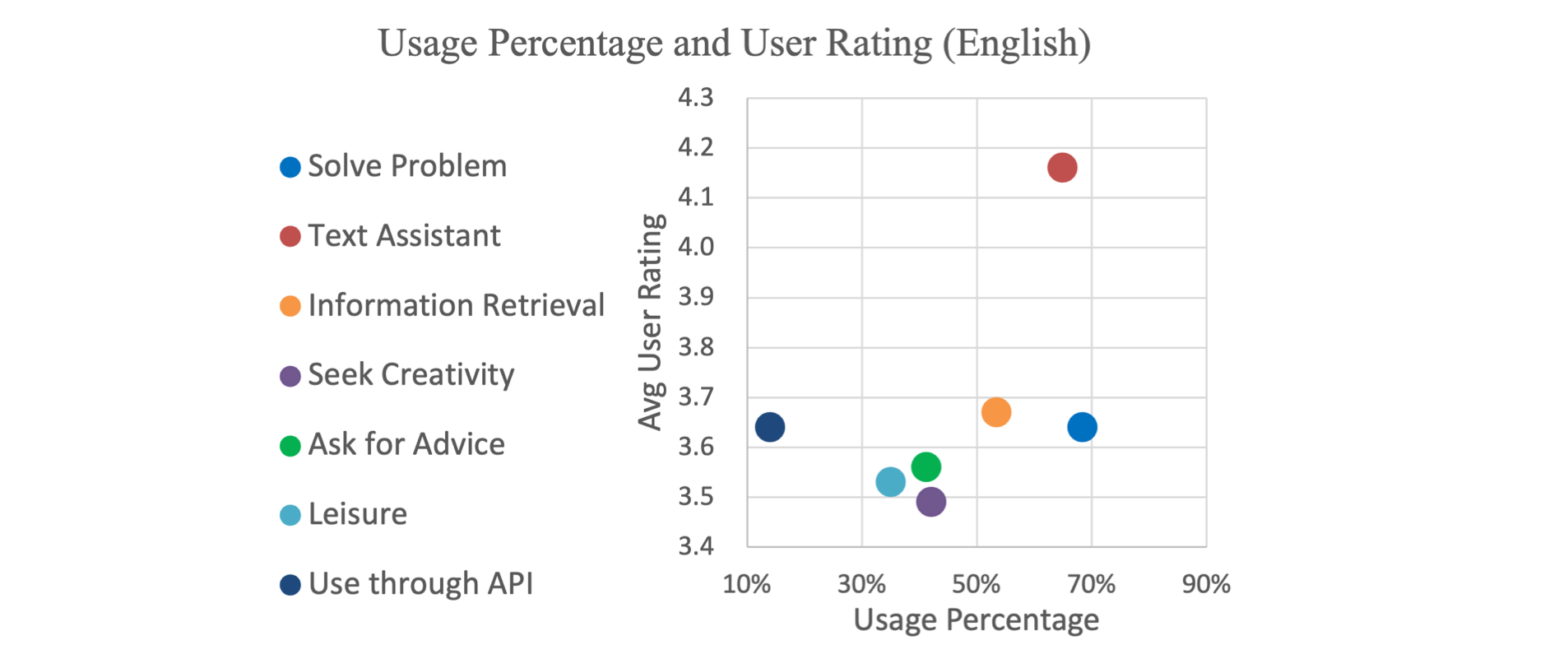
User Expectations vary greatly across scenarios, which might not always align with the current evaluation standards. Notice from the image below how the expectation of users differ based on the intent.

User concerns and desired improvements for large language models (LLMs) can be broadly classified into two categories: Capability and Trustworthiness.
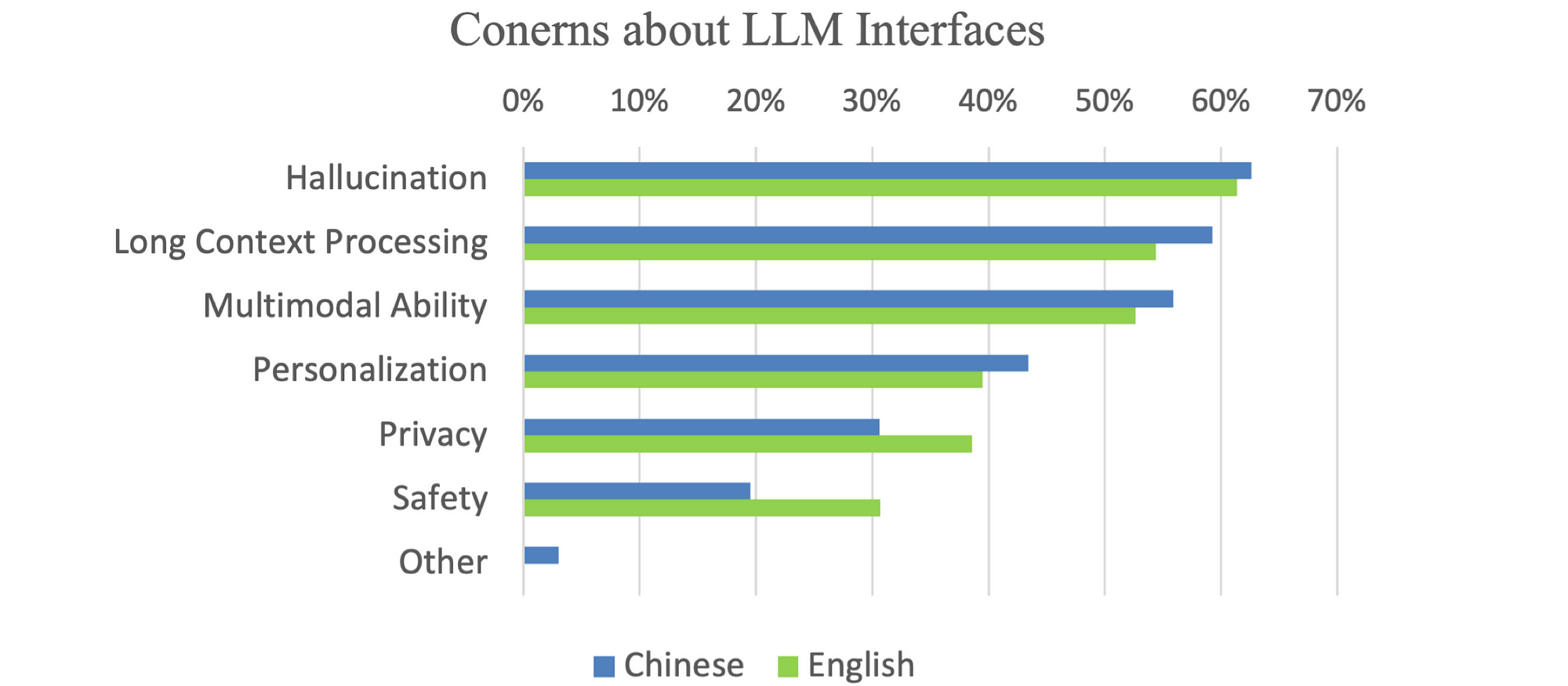
Finally
There are three ways in which LLMs are made available to users.
The LLM can be made available as a raw model, or exposed as an API, or the LLM can be exposed via UI as a personal assistant.
This study can serve as an invaluable resource to build better personal assistants making use of LLMs.
Find the study here.
Previously published on Medium.






